
There has been a global paradigm shift in cognitive science away from rule-based, symbolic architectures of the past century towards stochastic, often Bayesian, or connectionist models of human cognition. Theories explicating natural language grammar focused on rules of combination and interpretation of signs, i.e., pairs of linguistic forms (sounds) and meanings, would postulate symbolic grammar rules such as “combine unit A with unit B if some conditions are met to a new unit C with specified form and meaning”. By contrast, the stochastic paradigms focus on pattern recognition emerging from language use as mirrored in large collections of texts (corpora) without strict formal rules of combination. One culmination of this latter paradigm shift is the remarkable progress of AI in the domain of language generation, that has led many cognitive scientists to call into question the rule-based approach to natural language grammar predominant in linguistic research. Indeed, the most radical consequence of this paradigm shift would be that human language itself is conceptualized as fundamentally stochastic in nature and the apparent hard symbolic rules one may encounter in various syntactic or semantic domains represent nothing but limit cases in probability distributions.
The recently established Special Research Area (SRA) “Language between Redundancy and Deficiency” is an attempt to rethink the nature of human language grammar in the face of such advances by building on (rather than giving up) the core findings of symbolic grammar models. The overarching aim of the project is to develop a novel integrative paradigm of human language grammar that bridges between stochastic variation and a rule-based symbolic architecture of grammar. The stochastic cognitive environment is the broader, probabilistically driven neural-computational system which we assume to constitute the major part of (human) cognition. It relies on approximate, statistical computations (e.g., pattern recognition, Bayesian inference), and makes a noisy substrate driving robust communication and learning. With this approach, the SRA is attempting to find a new way to model the cognitive embedded nature of language.
A new perspective on the connection between language and broader cognition
Our fundamental hypothesis is that while language is embedded in a stochastic cognitive environment, it is itself not overall stochastic but has a symbolic grammatical core, akin to symbolic logic or mathematics. But how can a fundamentally rule-based, symbolic system be meaningfully integrated into a stochastic environment? In contrast to views where language is a separate module that is isolated from its cognitive environment, as originally proposed in pioneering work by Chomsky, we suggest that language as a rule-based system is adapted to its cognitive environment, while maintaining the non-stochastic core of grammar. This means that the rules of grammar are symbolic and deterministic, however their application is subject to flexibility as required by the cognitive environment. This flexibility is modelled by means of two fundamental cognitive categories that are built into linguistic rules: deficiency and redundancy.
- Deficiency states that an operation can be applied even if the input lacks certain features that it requires
- Redundancy states that an operation can be applied even if the input has features that it is not specified to take.
For example, there are many cases in natural language grammar, in which some features, such as gender or person, appear on a pronoun but are actually not interpreted. The English sentence Only I did my homework, has a natural reading that excludes that other people did their own respective homework – e.g. Only I did my homework. Peter and Mary did not do theirs. Crucially, in that reading the fact that my usually refers to first person is ignored. One can argue that the semantic rules governing the contribution of my in this example are redundant, because they ignore a formally visible feature. By contrast, we could also argue that the rules governing the formal spell-out of my are deficient, because they apply without the appearance of a first person feature at the level of meaning. It is not a priori clear which perspective is correct for such examples.
We suggest that these two properties of linguistic operations apply at all levels of representation from meaning to form. Our hypothesis is that by spelling out linguistic rules that incorporate deficiency and redundancy, this naturally gives grammar the flexibility to maximize efficiency within its cognitive environment.
Focus on shared memory
The model we propose places the core rule-based architecture of language within the cognitive environment of language, which is represented as stochastic shared knowledge of sounds and meanings:
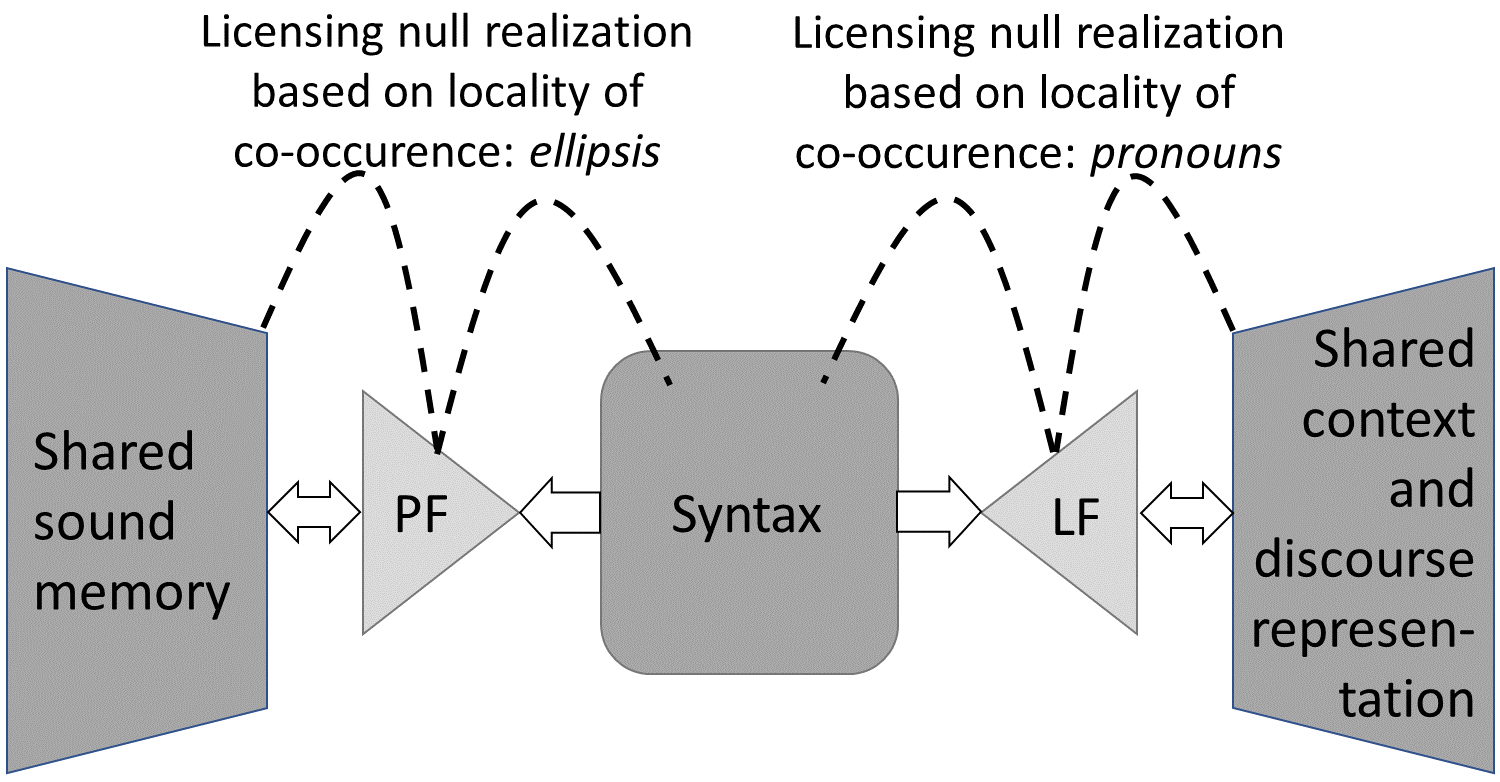 Shared knowledge encompasses, to different degrees, both ad hoc elements such as the last few utterances in discourse or memories of past discourses and the entire net of cultural practices from shared experiences to shared values, attunements and dispositions. The presence of shared sound thereby enables the reduction of formal operations (phonological form, PF), leading, broadly, to ellipsis; and shared meaning enables the reduction of semantic operations (logical form, LF), leading, broadly, to pronouns. Both ellipsis and pronouns are not just simple abstract categories, but actual categories of grammar such as personal pronouns, demonstratives, null-pronouns etc. and as such they are the natural grammatical testing ground for our theory development and constitute the main topic of the first 4-year phase of the SRA.
Shared knowledge encompasses, to different degrees, both ad hoc elements such as the last few utterances in discourse or memories of past discourses and the entire net of cultural practices from shared experiences to shared values, attunements and dispositions. The presence of shared sound thereby enables the reduction of formal operations (phonological form, PF), leading, broadly, to ellipsis; and shared meaning enables the reduction of semantic operations (logical form, LF), leading, broadly, to pronouns. Both ellipsis and pronouns are not just simple abstract categories, but actual categories of grammar such as personal pronouns, demonstratives, null-pronouns etc. and as such they are the natural grammatical testing ground for our theory development and constitute the main topic of the first 4-year phase of the SRA.
Future plans
The SRA, funded by the Austrian Science Fund (FWF), consists of 9 projects spread across the universities Graz, Vienna and Salzburg in Austria and the first 4-year phase of our work will end in February 2028. In the second phase, an overarching theory of grammar centered around the implementation of redundant and deficient rules will be developed that implements a novel linguistic theory of pronouns and ellipsis. Such an overall theory will enhance not only linguistic theory in the narrow sense but will contribute to our broader understanding of the cognitive embedding of language as a rule-based system which implements interfaces to a stochastic cognitive environment by means of the flexibility offered by redundant and deficient rules.





