")
By Andrew Lampinen
Banner image sketch by Natalia Vélez.
The flexibility of human cognition is remarkable. We can perform a new task (for example, playing a new videogame) decently after a few minutes of experience. We can then adapt our knowledge to new situations or goals, for example trying to lose the videogame we have been trying to win, or trying to teach it to a friend (Lake et al., 2017). While this flexibility is readily available to humans, modeling it turns out to be more difficult. Deep-learning models (connectionist neural networks with many layers) can achieve human-level performance in video games, but they require inhuman amounts of training to do so, such as 900 hours of game playing (Lake et al., 2017). Furthermore, even given enough data to achieve human-level performance in a task, they cannot flexibly adapt to changes of goals (Lake et al., 2017; Marcus, 2020).
However, I suggest that this is not a failure of neural network models themselves, but rather reflects the simplistic way these models are often trained. Their training is often missing key components of human experience that may contribute to our flexibility. In particular, I will highlight recent work showing three cognitively-relevant factors that can increase the flexibility of neural networks:
- Reframing the task — learning to be flexible rather than learning a particular skill.
- Environmental factors — embodiment and realism can improve flexibility.
- Scale & emergence — qualitative improvements can occur with changes of scale.
Below, I’ll discuss each factor, and how it relates to ideas from cognitive science.
1. Learning to be flexible
For concreteness, let us focus on a task which humans can perform well. We can learn a visual concept or category based on a few examples. Given the positive and negative examples in the figure below, you can probably infer the concept and correctly identify which of the test probes are members of the category:
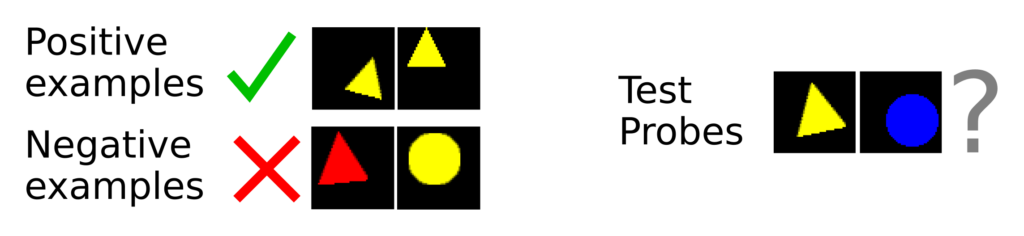
By contrast, neural network models often require datasets with thousands of images per class to learn visual concepts (e.g. Deng et al., 2009). However, we can reframe the task to allow the model to learn more efficiently.
In particular, instead of focusing on the task of learning a single visual concept, we can train the system to learn how to learn visual concepts rapidly from a few examples (see figure below for a comparison). That is, the model would be trained to receive a few positive and negative examples of different concepts, and then generalize to new probe examples.
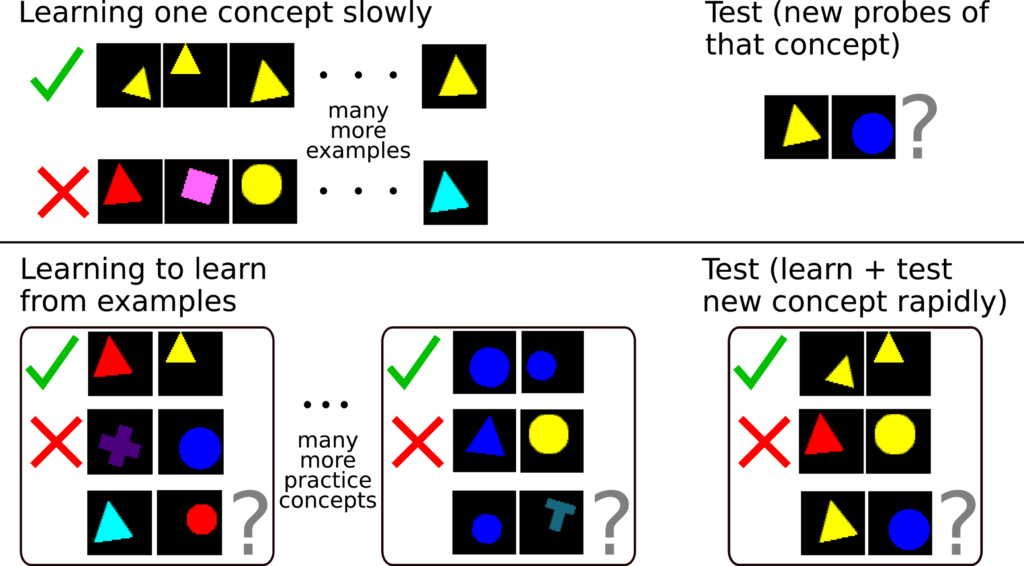
This reframing of the problem is generally referred to in machine learning as learning-to-learn, meta-learning, or few-shot learning. This approach can allow rapid learning of new tasks, including recognizing visual concepts from a few examples (e.g. Vinyals et al, 2016; Sung et al., 2018), or learning to efficiently explore new environments or discover the structure of reinforcement learning tasks (e.g. Wang et al.¸ 2016; Botvinick et al, 2019).
There are many other ways of reframing a task. For example, we could train a model to follow instructions to perform varied tasks (Larochelle et al., 2008; Hermann et al., 2017), or to infer a behavior from watching a human demonstration (Yu et al., 2018). In recent work, I’ve shown that a model can learn to perform new tasks on its first try based on their relationship to prior tasks (Lampinen & McClelland, under review). There are many ways in which a model could learn to be flexible.
I suggest that this approach of learning how to learn efficiently and behave flexibly is part of the structure of human developmental experience [1]. Indeed, a primary goal of education is to allow students to learn more efficiently, and apply their knowledge in future situations (Broudy, 1977; Bransford & Schwartz, 1999). For humans, like neural networks, learning efficiently and flexibly applying knowledge are skills that require practice.
2. Environmental factors can affect flexibility
However, tasks are not the only factor that contributes to flexibility. In recent work (Hill et al., 2020), my colleagues and I show that the environment in which a model is situated can substantially affect the model’s ability to flexibly perform new tasks. In particular, we showed that more realistic and embodied environments can yield more systematic, compositional language generalization — that is, the ability to correctly interpret instructions that recombine words in novel ways.
For example, in one experiment we trained a neural network to recognize objects that had both a shape and a color, such as red horses or purple guitars. The system received a language instruction like “get the red horse,” and then had to choose a red horse over other red objects or different-colored horses. We then evaluated the ability of the system to generalize to novel compositions, such as purple horses, unseen in training. Crucially, we compared two systems: an interactive agent that chose the object by walking to it, and a model that simply saw an image containing two objects and had to make a forced choice. We trained each on the same set of instructions, and evaluated them with the same set of novel compositions. The interactive agent generalized perfectly, while the image classifier performed above chance, but far from perfectly. While we don’t understand all the contributing factors, this may be in part because the interactive model gets more varied experience of each instruction during training, and effectively gets to “think about” its decision for longer before committing during evaluation. We also showed that other elements of realism and embodiment affected language generalization. For example, generalization was more systematic in an agent with an egocentric (first-person) perspective than an allocentric perspective.
Humans are also affected by seemingly irrelevant task details. For example, human generalization in arithmetic reasoning is affected by formally irrelevant factors like spacing of the symbols (Landy & Goldstone, 2007). Indeed, it is frequently suggested that embodiment is an essential part of cognition (Anderson, 2003), and that abstract knowledge is grounded in more basic perceptual-motor systems and concepts. For example, arithmetic relies on the approximate number system (the visual system for estimating the number of objects in a scene without counting, Brannon & Park, 1999), and automatic gestures may support reasoning and learning in mathematics and science (Goldin-Meadow, 1999). Neural networks may be able to reason more flexibly when they can base that reasoning in rich perceptual-motor knowledge, as humans do.
3. Scale can lead to the emergence of flexibility
A final factor that has recently been shown to contribute to generalization is scale — both the size of the architectures and the amount and richness of data in the datasets. A quantitative difference in scale can sometimes lead to the emergence of qualitatively different behavior. Even a simple task, at scale, can yield complex behavior.
For example, imagine a model that is trained to read and constantly predict the next word it will hear [2]. Although this is a simple task, at some level it captures much of the complexity of language. If such a model were sufficiently accurate, it would need to understand arithmetic in order to predict the words following the sentence below:
Forty-five plus sixty-two is …
It would also need to understand the relationship between English and French to predict the words following:
To say “I went to the bank” in French, you say “Je …
Would such a model actually show this knowledge? In fact, the GPT-3 language model (Brown et al., 2020) demonstrates both of these abilities, and many more. With appropriate prompting, it can write Shakespearian poetry, translate natural language into code in javascript, python, or SQL, or diagnose patients from a description of symptoms (see https://github.com/elyase/awesome-gpt3 for these and many more examples). Many behaviors can emerge from learning simple word-prediction to high accuracy.
However, the scale of language that GPT-3 learns from far exceeds what any human could experience. This is likely necessary in part because of other limitations of its training. Its task is simple, and it lacks the rich grounding and embodiment that contribute to human learning. Furthermore, while GPT-3’s 175 billion parameters may seem staggering, it is still several orders of magnitude smaller than the hundreds of trillions of synapses in the human brain (and the complexity of synapses, glial computation, etc. may increase our effective number of parameters further). This is a critical difference, because larger models can generalize substantially better from the same amount of data (Kaplan et al., 2020). Generalization can emerge with model scale and data complexity.
Conclusion
At present, none of the computational approaches I’ve described in this post have achieved fully human-like flexibility. But they illustrate a path by which to pursue it. How flexible could a neural-network model be when trained with more human-like tasks, in more human-like environments, at a more human-like scale? That is an exciting question, which I hope we will learn more about over the coming years.
Notes
[1] Of course, some of this “learning” to be efficient learners may occur over evolutionary time, rather than developmental time. Still, there is substantial development within the lifetime.
[2] Note that state-of-the-art language models in fact predict pieces of words, rather than a whole word at a time, which allows them to exploit all the patterns in how words are constructed.
References
Anderson, M. L. (2003). Embodied cognition: A field guide. Artificial intelligence, 149(1), 91-130.
Botvinick, M., Ritter, S., Wang, J. X., Kurth-Nelson, Z., Blundell, C., & Hassabis, D. (2019). Reinforcement learning, fast and slow. Trends in cognitive sciences, 23(5), 408-422.
Bransford, J. D. and Schwartz, D. L. (1999). Rethinking Transfer: A Simple Proposal With Multiple Implications. Review of Research in Education, 24(1):61–100.
Broudy, H. S. (1977). Types of knowledge and purposes of education. In R. C. Anderson, R. J. Spiro, & W. E. Montague (Eds.), Schooling and the acquisition of knowledge (pp. 1-17).
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255).
Goldin-Meadow, S. (1999). The role of gesture in communication and thinking. Trends in Cognitive Sciences, 3(11):419–429.
Hermann, K. M., Hill, F., Green, S., Wang, F., Faulkner, R., Soyer, H., … & Wainwright, M. (2017). Grounded language learning in a simulated 3d world. arXiv preprint arXiv:1706.06551.
Hill, F., Lampinen, A., Schneider, R., Clark, S., Botvinick, M., McClelland, J. L., & Santoro, A. (2020). Environmental drivers of systematicity and generalization in a situated agent. In International Conference on Learning Representations.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2017). Building machines that learn and think like people. Behavioral and brain sciences, 40.
Lampinen, A. K., & McClelland, J. L. (under review). Transforming task representations to allow deep learning models to perform novel tasks. arXiv preprint: https://arxiv.org/abs/2005.04318.
Landy, D., & Goldstone, R. L. (2007). How abstract is symbolic thought?. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(4), 720.
Larochelle, H., Erhan, D., & Bengio, Y. (2008, July). Zero-data learning of new tasks. In AAAI (Vol. 1, No. 2, p. 3).
Marcus, G. (2020). The next decade in AI: Four steps towards robust artificial intelligence. arXiv preprint arXiv:2002.06177.
McClelland, J. L. (2010). Emergence in cognitive science. Topics in cognitive science, 2(4), 751-770.
Park, J. and Brannon, E. M. (2013). Training the Approximate Number System Improves Math Proficiency. Psychological Science, 24(10):2013–2019.
Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P. H., & Hospedales, T. M. (2018). Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1199-1208).
Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. In Advances in neural information processing systems (pp. 3630-3638).
Wang, J. X., Kurth-Nelson, Z., Tirumala, D., Soyer, H., Leibo, J. Z., Munos, R., … & Botvinick, M. (2016). Learning to reinforcement learn. arXiv preprint arXiv:1611.05763.
Weber, K. (2001). Student difficulty in constructing proofs: The need for strategic knowledge. Educational studies in mathematics, 48(1), 101-119.
Yu, T., Finn, C., Xie, A., Dasari, S., Zhang, T., Abbeel, P., & Levine, S. (2018). One-shot imitation from observing humans via domain-adaptive meta-learning. arXiv preprint arXiv:1802.01557.


