
How do we name things? Why is this question interesting? Let’s make an experiment. Look at the two images below: If you had to give a name to the animals in the red frames, which names would you choose? We have asked this question to many people, and found out that the image on the left is called “bird” more often than “duck”, while the image on the right is called “duck” more often than “bird”. Still, both names are produced by a number of speakers (see counts in parentheses, below the images). Then, why is the duck on the right, in some sense, more of a duck than the one on the left? This kind of questions are central to the naming problem, which holds the interest of curious people since Plato’s times, talking about how we categorize the world through human lenses.

Figure 1: Images are from the ManyNames dataset (Silberer et al., 2020).
Early studies in Psycholinguistics (Jolicoeur et al., 1984; Rosch and Mervis, 1975; Rosch et al., 1976) focused on how humans categorize objects “cutting up the environment into classifications”¹. They suggested that the typicality – or prototypicality – of the objects for their category may influence the way we call them: Speakers generally show a preference for names that correspond to an intermediate level of specificity – the so-called basic level. As a consequence, the name “bird” is often preferred over “sparrow” or “animal” (Jolicoeur et al., 1984) . However, things seem to be different for some objects, for which a subordinate level of classification tends to be preferred. A famous example of this phenomenon is the case of penguins: They could legitimately be called “birds”, but people seem to prefer a more specific name because penguins are atypical birds. As we have just seen, this line of research mainly focused on concepts and categories, stressing that, for example, penguins and ducks are atypical for their category “bird”: They don’t show the prototypical features of birds, such as having proper wings to fly.
But what about the two ducks above, then? In this case, we are looking at two different instances of the same category, with a different degree of typicality for the names “duck” and “bird”: To be able to explain why these two ducks show different degrees of naming variation, we need to move our focus to the level of the instances, and study their different relationship with categories.

Figure 2: Examples of stimuli employed in naming studies. In panel (a), the stylized black-and-white stimuli used by Snodgrass and Vanderwart (1980). In panel (b), the photorealistic images used by Brodeur et al. (2014)
How can we translate this into an experimental study? How can we empirically represent categories? For decades, simplified stimuli have been at center stage, as place-holders for categories. Scientists (Alario and Ferand, 1999; Brodeur et al., 2010; Snodgrass and Vanderwart, 1980; Tsaparina-Guillemard et al., 2011) have relied on standardized image sets, designing visual stimuli meant to be as prototypical as possible. The task of creating these prototypical stimuli was sometimes carried out by illustrators, specifically instructed to use the same graphic style throughout the depictions and to avoid depicting any unnecessary object attributes (Berman et al., 1989). Sometimes, photorealistic stimuli were generated by normalizing and simplifying pictures with computer softwares (Brodeur et al., 2010). Usually, only one depiction per category was included: Different instantiations of the same category, like the two ducks above, were disregarded as source of noise, chasing after the most prototypical representation possible. In short, with the simplified stimuli framework, we would not be able to account for what happens with our two ducks.
Today we can chase for concepts and instances in a different manner. Thanks to Computer Vision, representing a concept may not be a problem anymore, and the specific differences shown by objects of the same category may be a resource – and not a limitation! – for research on naming. To understand why, we need to briefly dive into AI.
Computer Vision systems are trained with large amounts of images to solve specific tasks. Common tasks are, for instance, object recognition and image captioning. In object recognition tasks, the machine is tasked to output a category for a given object depicted in an image. Instead, in image captioning tasks, the system has to produce a phrase or a sentence to describe the image content. As part of carrying out these tasks, these models learn distributed representations of the images they see. Let’s understand what this means with an example.
We have here 3 images of dogs, i.e. 3 instances of the category “dog”. We can describe them in terms of visual features: In this case, say we have 3 features: having two ears, being white, and sitting. We can give a score to each dog for each of our features, by checking how much of the visual features it shows. For instance, we can certainly give the same score to all the dogs for having two ears. With respect to being white, instead, we can give a high score to dog 2, a very low score to dog 3, and an intermediate score to dog 1. The rows of the table that we have filled are similar in their nature to the multi-dimensional vectors that computational systems learn, encoding in numbers pieces of visual information about the image content, such as corners, edges, or colors.

Figure 3These representations show interesting properties: If we compare them (this is usually done through cosine similarity), we obtain that images with more similar vector representations tend to be judged as more similar by human annotators as well (Zhang et al., 2018). Look at the table reporting similarity scores in the image: We can see that dog 1 and dog 2 obtain a higher similarity score based on their vector representations than, for instance, dog 1 and dog 3. This makes sense since dog 3 shares only one visual property with dog 1 (having two ears), while dog 2 shares with dog 1, to some degree, all the 3 visual properties.
Now it should be clear why Computer Vision tools can be an important resource when answering questions about human naming behavior: We can quickly obtain representations for all the objects depicted in large-scale image datasets (i.e. our instances, and use them to address problems concerning the connection between language, vision, and the conceptual system.
Starting from the instances, we can represent concepts as well. To obtain the representation of a concept, e. g. “dog” or “duck”, we can compute the average representation of many objects that have been called with that name (Gualdoni et al., 2022). The result of this operation will be a synthetic representation that summarizes the visual features most commonly associated with dogs and ducks – what we call a prototype. We can finally overcome the problem of deciding on what is prototypical or not for a category – and stop bothering illustrators: We can infer prototypicality from the data.
At this point, we have in our hands a (cheap and fast) measure of object typicality for any name we want: We can compute the similarity between the representation of the object instance and the prototype for any name in our vector space. As illustrated in Figure 4, a golden-retriever (on the left) will have a representation that is more similar to the prototype of the name “dog” than a toy dog (on the right). Therefore, the golden-retriever will get a higher typicality score for this name. Imagine that now we want to give these two dogs a score for their typicality for the name “toy”: We can apply the same operation, and we would probably obtain the opposite result.
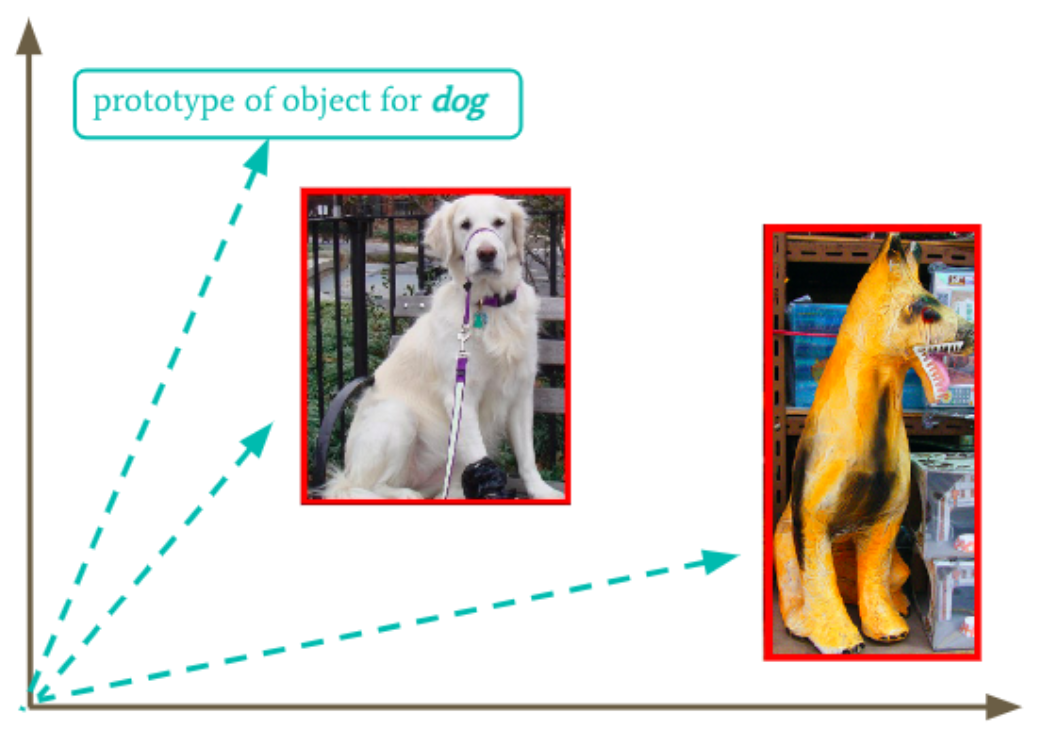
Figure 4: Computational method to estimate the typicality of a given object for a given name.
In my lab, we used tools of this kind to study what causes people to disagree when naming objects. We discovered that, when different speakers are asked to name an object, the competition between name candidates determines speakers’ disagreement in their naming choices. This competition is triggered by what the object looks like: If its visual appearance is prototypical for many candidate names, or if it is not really typical for any candidate, then speakers will be likely to produce many different names for it. In contrast, if the object is clearly closer to one prototype than to the other ones, people will more probably converge on that one name for it. See the illustration below: We plotted in 2D the vector representation of many instances of “bench”, “chair”, “couch”, and “sofa” (see colored dots) together with the corresponding prototypes (see blue triangles). Look at the position that the two “bench” objects depicted in the images obtain in the visual vector space: The object on the right, that has received many different names by speakers, is placed in between multiple prototypes, i.e. candidate names that are similarly plausible. This can explain why speakers produce a rich array of names for this object – and not for the bench on the left.
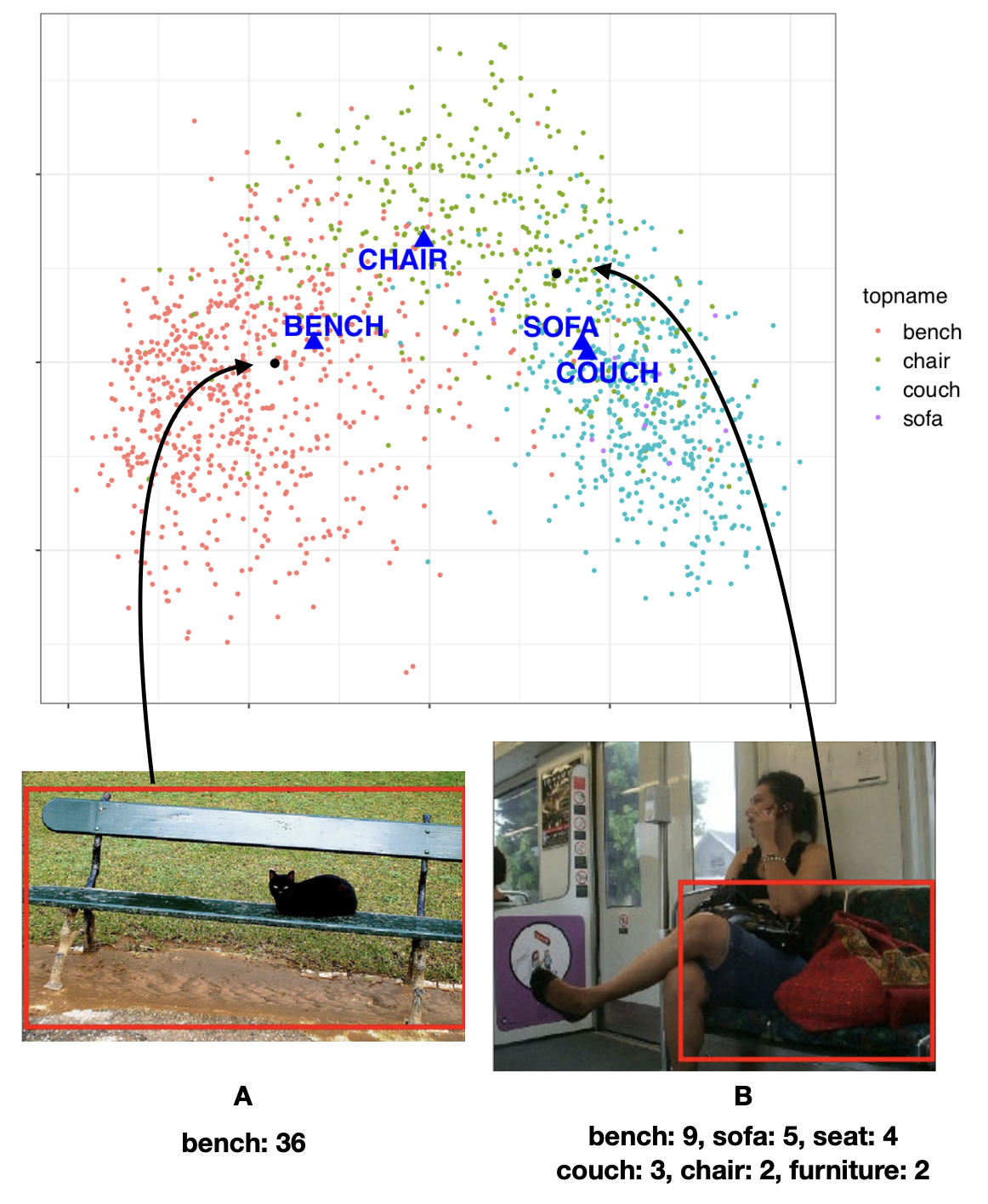
Figure 5: Visual space corresponding to images named “bench”, “couch”, “sofa”, and “chair”. Prototypes are represented by blue triangles. Dots represent objects. They are colored based on their top name. Images A and B show two objects framed in a red bounding box. The names produced for the objects are listed below the images, followed by response counts.
Many analysis paths are afforded by this computational method, paired with real-world images: For instance, we have processed the context in which the objects appear with a Computer Vision system, thus obtaining vector representations for contexts as well, in addition to objects. With these representations, we have been able to compute context prototypes for the names – again as averages – and to automatically obtain context typicality scores. With this procedure, we have been able to show that context properties matter as well. Recall the example of the two ducks above: In the image on the right, the pres- ence of the ducklings following the duck may play a role in driving speakers’ choice towards the name “duck”, because this is a very prototypical scene ducks appear in.
We have been able to run large-scale analyses and enrich our knowledge of human naming behaviour thanks to computational tools. Until a few years ago, a large-scale analysis comparing object instances with concepts would not have been possible. Similarly, estimating the competition between names that takes place when speakers name an object would have been a hard task. New methods allow to explore old problems from new angles. We believe that Computer Vision, and Computer Science in general, can help informing Cognitive Science theories, by providing efficient and non-costly instruments to tackle new challenges. It’s time to be creative.
To read more about this:
• https://psyarxiv.com/t84eu/
• https://psyarxiv.com/34ckf/
1. Rosch et al. 1976, p. 382

References
Alario, F. X. and Ferrand, L. (1999). A set of 400 pictures standardized for french: Norms for name agreement, image agreement, familiarity, visual complexity, image variability, and age of acquisition. Behavior Research Methods, Instruments, & Computers, 31:531–552.
Berman, S., Friedman, D., Hamberger, M. J., and Snodgrass, J. G. (1989). Developmental picture norms: Relationships between name agreement, fa- miliarity, and visual complexity for child and adult ratings of two sets of line drawings. Behavior Research Methods, Instruments, & Computers, 21:371– 382.
Brodeur, M., Dionne-Dostie, E., Montreuil, T., and Lepage, M. (2010). The bank of standardized stimuli (boss), a new set of 480 normative photos of objects to be used as visual stimuli in cognitive research. PloS one, 5:e10773.
Brodeur, M., Gu ́erard, K., and Bouras, M. (2014). Bank of standardized stimuli (boss) phase ii: 930 new normative photos. PloS one, 9:e106953.
Gualdoni, E., Brochhagen, T., M ̈adebach, A., and Boleda, G. (2022). Woman or tennis player? Visual typicality and lexical frequency affect variation in object naming. In Culbertson, J., Perfors, A., and Rabagliati, H. & Ramenzoni, V., editors, Proceedings of the 44th Annual Conference of the Cognitive Science Society. Cognitive Science Society.
Jolicoeur, P., Gluck, M. A., and Kosslyn, S. M. (1984). Pictures and names: Making the connection. Cognitive Psychology, 16(2):243–275.
Rosch, E. and Mervis, C. B. (1975). Family resemblances: Studies in the internal structure of categories. Cognitive Psychology, 7(4):573–605.
Rosch, E., Mervis, C. B., Gray, W. D., Johnson, D. M., and Boyes-Braem, P. (1976). Basic objects in natural categories. Cognitive Psychology, 8:382–439.
Silberer, C., Zarrieß, S., and Boleda, G. (2020). Object naming in language and vision: A survey and a new dataset. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 5792–5801, Marseille, France. European Language Resources Association.
Snodgrass, J. G. and Vanderwart, M. (1980). A standardized set of 260 pic- tures: norms for name agreement, image agreement, familiarity, and visual complexity. Journal of experimental psychology. Human learning and mem- ory, 6 2:174–215.
Tsaparina-Guillemard, D., Bonin, P., and M ́eot, A. (2011). Russian norms for name agreement, image agreement for the colorized version of the snod- grass and vanderwart pictures and age of acquisition, conceptual familiarity, and imageability scores for modal object names. Behavior research methods, 43:1085–99.
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. (2018). The unreasonable effectiveness of deep features as a perceptual metric.


